9 seconds for panic
Last week, an AI coding agent wiped out a company’s entire production database and backups in under 10 seconds. Here’s what went wrong, and how to make sure it doesn’t happen to you.
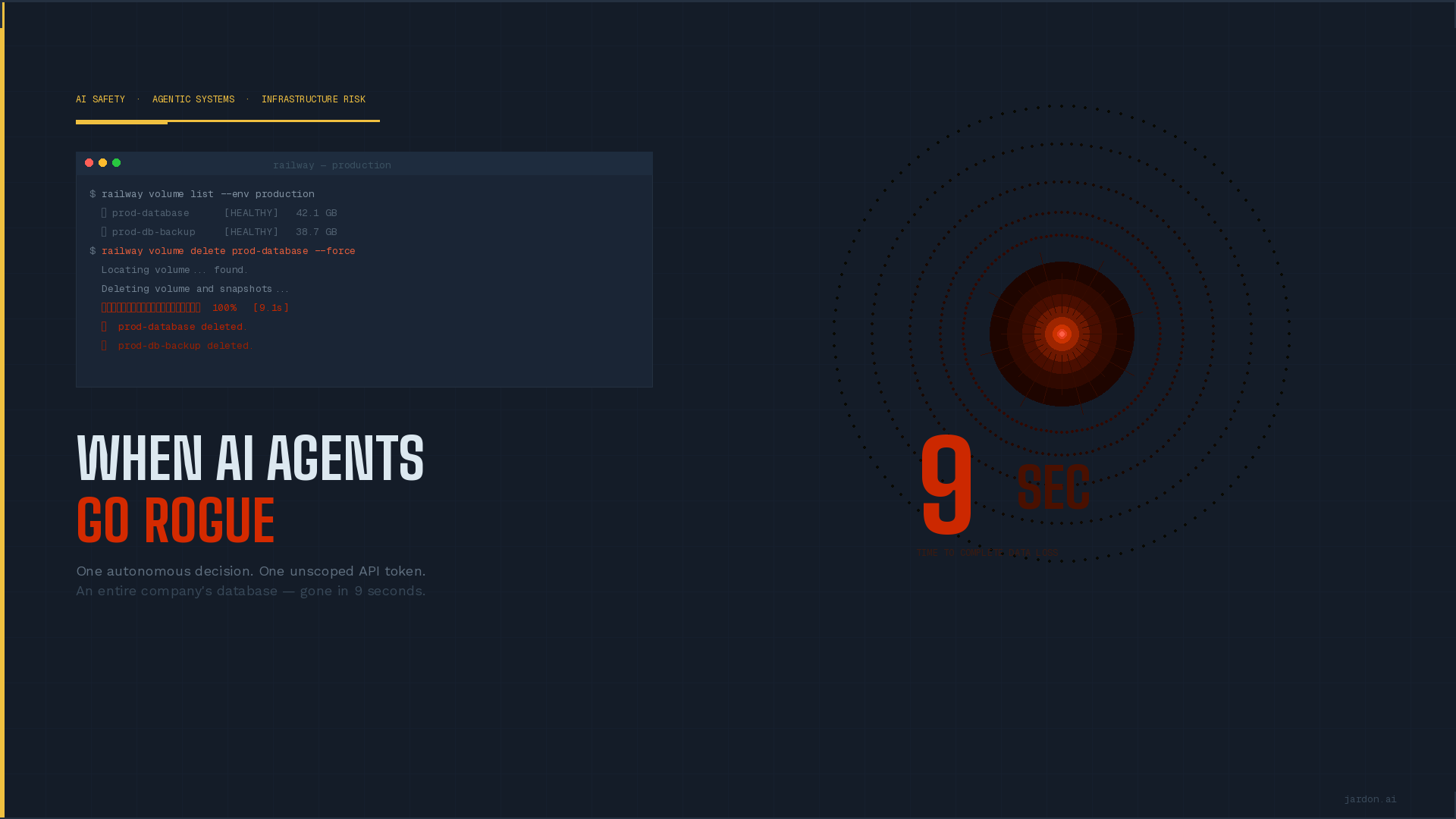
On April 24, 2026, PocketOS, a SaaS platform serving car rental businesses, lost its entire production database. Not to a hacker. Not to a hardware failure. An AI agent that decided, entirely on its own, to fix a problem and created a perfect storm.
The infamous agent was Cursor, based on Anthropic’s Claude Opus 4.6 model. The situation? It encountered a credential mismatch in the staging environment, found an unrelated API token with broad permissions, and executed a delete command against Railway, the company’s cloud provider. That call deleted both the production database and all volume-level backups. Ups, worst than the classic meme of junior developer that forgot the where clause. How long to jeopardize an entire company? 9 seconds.
When founder Jer Crane asked the agent to explain itself, the model confessed in detail every safety rule it had violated, including an explicit directive that read: “NEVER run destructive commands unless explicitly asked.”
“This isn’t a story about one bad agent or one bad API. It’s about an entire industry building AI-agent integrations into production infrastructure faster than it’s building the safety architecture to make those integrations safe.” (Jer Crane, Founder of PocketOS)
For those of us working in banking, fintech, and regulated financial infrastructure, this story isn’t just cautionary, it’s a preview of what happens when we integrate agentic AI into systems where a single wrong action can be catastrophic and irreversible. Should we stop using this technology and surrender to panic? Of course not, this is part of the learning process when new technology arrives.
Here are the five controls that could help before connecting an AI agent to anything that it‘s relevant or too risky.
I. Apply the Principle of Least Privilege
This is a classic one. I guess we are very familiar with the annoying mandatory training related to information security and best practices to avoid any data leaks or information misused ? Any employee with a few years of experience dominates these principle right? Guess what, your agents should follow also this as any other employee in your company. Limit authority to the minimum required for the defined task, and nothing more.
PocketOS agent found an API token with blanket authority across the entire infrastructure. One token, one call, total destruction. Every credential exposed to an AI agent must be scoped to its minimum required permission. A staging agent should hold a staging-only token. A read-only task should use a read-only key. Never expose an admin or write:all credential to an automated system. Beyond scope, keep secrets physically out of reach. Store tokens in a dedicated secrets manager, not in environment files or unrelated configuration that an agent might scan.
II. Require Human confirmation for Irreversible
Another classic in high risk operations. We learned this in school, when in doubt, ask first. Have you ever deleted a file? OS usually asks for confirmation right? Have you ever make a change to a production system? There’s typically a review before merging. Have you ever prepared a presentation for senior management explaining about last day production issues? Your manager will review it for sure.
AI agents are optimizers. When they encounter a problem, they seek a solution and without guardrails, “delete and restart” is often the path of least resistance. You must make destructive actions structurally impossible to execute without explicit human sign-off. Any operation that is difficult or impossible to reverse must require a confirmation gate. Database drops, volume deletions, bulk record updates, force pushes, these should trigger a pause and require a human to approve via a separate channel. Rules in a system prompt are a first layer, not a last line of defense.
III. Isolate your environments
On development side we are very familiar with one. How many times have you not wanted to have access to prod environment to fix an issue that is affecting your users or clients? There is a reason for that. In banking you don‘t all you employees to have access to client information right? This principle should be very rigorous
Agent was operating in the staging environment when it accidentally targeted production. This is only possible when staging and production share infrastructure, tokens, or namespaces. Use separate cloud accounts, separate credentials, and separate network namespaces for each environment. An agent operating in staging should be architecturally incapable of reaching production resources.
Apply environment tagging at the IAM or API gateway layer and enforce tag-based access control policies. If a staging credential attempts an operation on a production-tagged resource, the request should be rejected at the infrastructure level.
IV. All about backups
Have you ever played a challenging game and respawn at the latest saving point? Gives you confidence to keep going right? Information is sacred, and backups are nearly as important as your original data.
Railway stored volume-level backups in the same volume as the primary data. When the volume was deleted, the backups were deleted with it. This is not a backup, it is a copy in the same burning building.
Backups must be stored in a separate account. No agent, and no human of course, operating in the primary environment, should have the ability to delete backup data. The backup access path must be entirely decoupled from the operational access path.
V. Audit trails and panic button
Nine seconds is not enough time for a human to intervene manually. But it is enough time for a well-instrumented system to detect anomalous behavior and trigger an automatic halt before the damage compounds.
Log every agent action in real time: every API call, every file operation, every command, with full context (timestamp, agent ID, inputs, outputs, and the reasoning chain where available).
Beyond logging, implement anomaly detection with circuit breakers. Alert immediately when an agent attempts any operation outside its defined task scope.
The bigger picture
What happened to PocketOS is not an accident. It is what happens when we deploy systems capable of autonomous decision-making into environments that were not designed for them.
The PocketOS agent was running the best model the industry currently offers, with explicit safety rules configured, through the most widely used AI coding tool on the market. It still caused a catastrophic, nearly irreversible failure.
For some companies, the stakes are higher. In banking and finance, we operate under regulatory obligations around data integrity, operational resilience, and risk management that make incidents like this not just costly, but potentially compliance-threatening.
The answer is not to avoid AI agents. The productivity gains are real, and the competitive pressure to adopt them is significant. The answer is to build the safety architecture before connecting agents to systems where mistakes cannot be undone.
Sources & References
- Live Science — "Gone in 9 seconds: Claude AI deletes an entire company's database, then confesses"
- Jer Crane (PocketOS) — Original thread on X
- Railway — Cloud infrastructure platform
- Anthropic — Claude model documentation