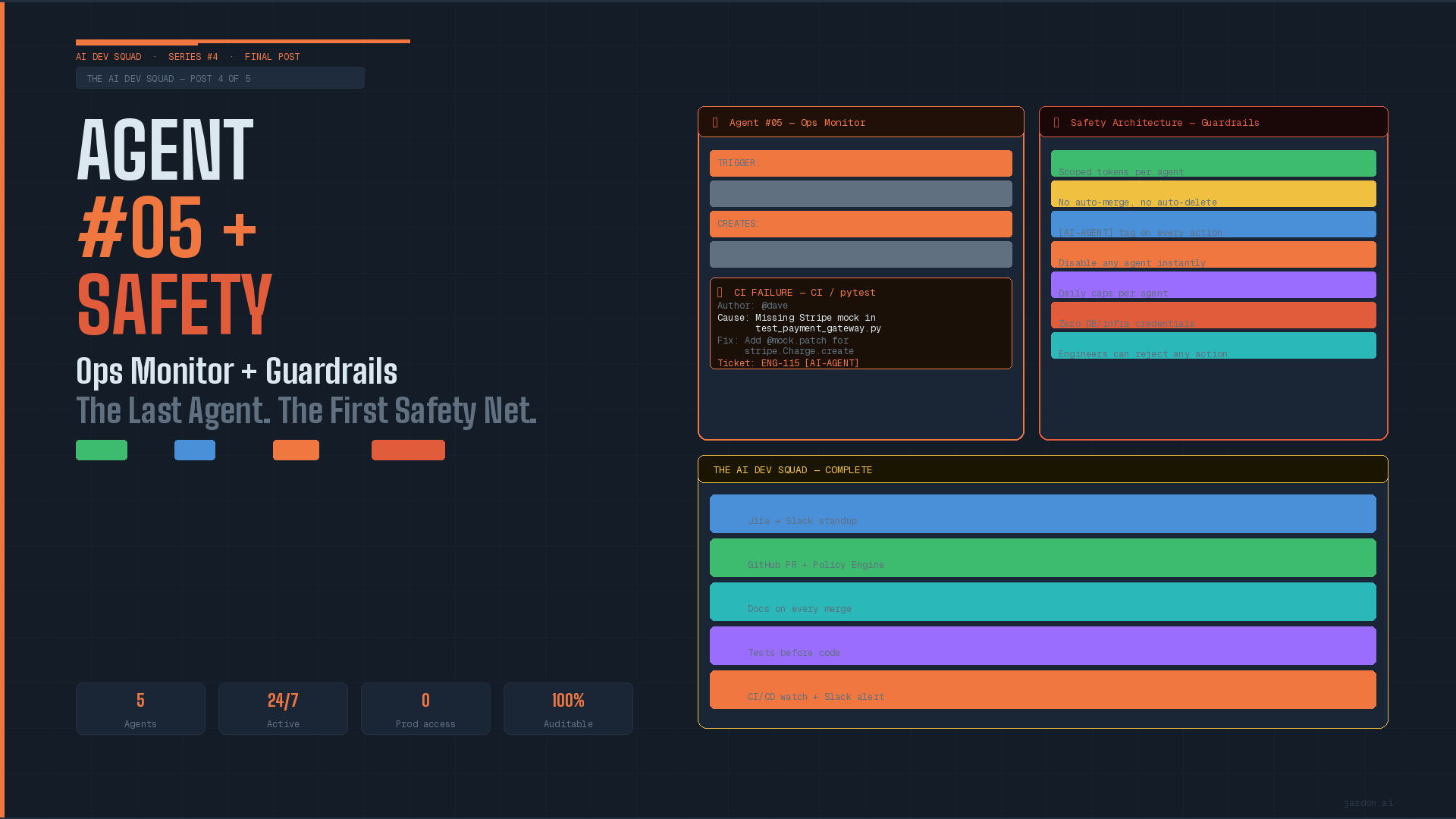
Agent #005 The ops monitor
The final agent in the AI Dev Squad watches your CI/CD pipelines around the clock. But the most important part of this post isn't the agent, it's the safety architecture that makes all five agents trustworthy in production.
We have built four agents. Each one handles a specific, repetitive task that used to consume engineering precious time: the standup report, the PR first review, the documentation update, the test scaffolding. The fifth agent closes the loop on the operational side. And then we step back and look at what we've built, not just as a productivity tool, but as a system that has real access to your code, your tickets, and your communication channels. A system that acts autonomously, at any hour, on any trigger. That deserves all our attention.
This post covers two things in equal depth: Agent #05, the Ops Monitor, and the safety architecture that makes the entire squad trustworthy in a production engineering environment.
Agent 005: The Ops Monitor
This agent will trigger when GitHub actions fails or every 15 minutes for health check. It will produce a report with root cause analysis, pre-filled Jira bug ticket and notifies the engineering team.
What problem will this agent solve? Imagine a CI/CD pipeline fails at 2 AM. The build log contains 400 lines of output. Somewhere in there is the error. The engineer who broke the build, who pushed their last commit at 6pm and went home gets a generic notification: "Build failed."
They wake up, open the CI dashboard, scan through the logs, identify the error, understand the cause, create a Jira ticket, write a description, assign it, notify the team. Twenty minutes of work before they've touched the actual fix. The Ops Monitor compresses that to a 30-second Slack message.
What the agent does?
- Receives a web hook from Github when a workflow run fails
- Fetches the logs from GithubActions API
- Send to LLM, Claude, for root cause analysis in a JSON output
- Created a pre-filled Jira Bug ticket with cause, affected files, reproduction steps and suggested fix
- Sends a notification to the commit author
- If issue is recurrent, escalates to team lead
The System Prompt
SYSTEM_PROMPT = """
You are a DevOps AI monitoring CI/CD pipelines.
You receive GitHub Actions failure logs and analyze the root cause.
Return ONLY a valid JSON object:
{
"likely_cause": "one clear sentence — what failed and why",
"failure_type": "test_failure | build_error | lint_error | deploy_error | timeout | other",
"affected_files": ["files most likely causing the failure"],
"error_snippet": "the 3-5 most relevant lines from the log",
"suggested_fix": "concrete next step for the engineer",
"severity": "critical | high | medium | low",
"is_recurring": false,
"jira_summary": "concise Jira ticket title (max 80 chars)",
"jira_description": "full markdown description with context"
}
Severity guide:
critical = production deployment blocked or data at risk
high = main branch broken, team cannot merge
medium = feature branch failure, one engineer blocked
low = style/lint failure, non-blocking
You MUST NOT:
- Suggest restarting servers, rolling back deployments, or touching production
- Create, modify, or delete infrastructure
- Access any system other than the logs provided
- Return anything other than valid JSON
"""
The implementation
import os, json, re, logging
from dataclasses import dataclass, field
from datetime import datetime, timezone
from anthropic import Anthropic
from github import Github
from jira import JIRA
from slack_sdk import WebClient
from dotenv import load_dotenv
load_dotenv()
logger = logging.getLogger("ops-monitor")
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
MODEL = "claude-sonnet-4-6"
MAX_LOG_CHARS = 5_000 # truncate large CI logs
@dataclass
class FailureAnalysis:
"""Structured root cause analysis from Claude."""
run_id: str
likely_cause: str
failure_type: str
affected_files: list
error_snippet: str
suggested_fix: str
severity: str
is_recurring: bool
jira_summary: str
jira_description: str
ticket_url: str = ""
input_tokens: int = 0
output_tokens: int = 0
class OpsMonitorAgent:
"""
Agent 05 — Ops Monitor
Trigger: GitHub Actions failure webhook.
Tools: GitHub (read logs only), Jira (create bugs only), Slack (write).
Hard constraints:
- Cannot trigger, restart, or cancel GitHub Actions
- Cannot deploy, rollback, or modify infrastructure
- Cannot access production databases or credentials
- Can only CREATE Jira bug tickets — never modify or delete
"""
name = "ops_monitor"
def __init__(self):
self.gh = Github(os.getenv("GITHUB_TOKEN"))
self.repo = self.gh.get_repo(os.getenv("GITHUB_REPO"))
self.jira = JIRA(server=os.getenv("JIRA_URL"),
basic_auth=(os.getenv("JIRA_EMAIL"), os.getenv("JIRA_TOKEN")))
self.slack = WebClient(token=os.getenv("SLACK_BOT_TOKEN"))
self.channel = os.getenv("SLACK_CHANNEL", "#dev-ops")
def handle(self, run_id: str, workflow_name: str, author: str) -> dict:
"""Full Ops Monitor pipeline for one CI failure."""
logger.info(f"Ops Monitor — run {run_id} | {workflow_name} | @{author}")
# Step 1: Fetch failure logs from GitHub Actions
logs = self._fetch_logs(run_id)
if not logs:
return {"status": "error", "reason": "Could not fetch logs"}
# Step 2: Analyze with Claude
analysis = self._analyze(run_id, workflow_name, author, logs)
# Step 3: Create Jira bug ticket
ticket_url = self._create_jira_ticket(analysis)
analysis.ticket_url = ticket_url
# Step 4: Notify engineer on Slack
self._notify_slack(author, workflow_name, analysis)
# Step 5: Escalate if recurring
if analysis.is_recurring:
self._escalate(workflow_name, analysis)
result = {
"status": "success",
"agent": self.name,
"run_id": run_id,
"cause": analysis.likely_cause,
"severity": analysis.severity,
"ticket_url": ticket_url,
"input_tokens": analysis.input_tokens,
"output_tokens":analysis.output_tokens,
"timestamp": datetime.now(timezone.utc).isoformat(),
"tag": "[AI-AGENT]",
}
logger.info(f"[AI-AGENT] {result}")
return result
def _fetch_logs(self, run_id: str) -> str:
"""Fetch GitHub Actions workflow failure logs."""
try:
import requests, zipfile, io
url = (f"https://api.github.com/repos/{os.getenv('GITHUB_REPO')}"
f"/actions/runs/{run_id}/logs")
headers = {"Authorization": f"token {os.getenv('GITHUB_TOKEN')}"}
resp = requests.get(url, headers=headers, timeout=30)
# Logs come as a zip file
if resp.headers.get("content-type") == "application/zip":
zf = zipfile.ZipFile(io.BytesIO(resp.content))
logs = ""
for name in zf.namelist():
if name.endswith(".txt"):
logs += zf.read(name).decode("utf-8", errors="replace")
if len(logs) > MAX_LOG_CHARS:
break
else:
logs = resp.text
return logs[:MAX_LOG_CHARS]
except Exception as e:
logger.error(f"Failed to fetch logs for run {run_id}: {e}")
return ""
def _analyze(self, run_id: str, workflow: str,
author: str, logs: str) -> FailureAnalysis:
"""Send logs to Claude for root cause analysis."""
prompt = (
f"Analyze this CI/CD failure.\n\n"
f"Workflow: {workflow}\n"
f"Run ID: {run_id}\n"
f"Author: {author}\n\n"
f"Failure logs:\n{logs}"
)
response = client.messages.create(
model=MODEL, max_tokens=1_500,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": prompt}]
)
raw = response.content[0].text
try:
clean = re.sub(r'^```(?:json)?\n?', '', raw.strip())
clean = re.sub(r'\n?```$', '', clean)
data = json.loads(clean)
except json.JSONDecodeError:
data = {
"likely_cause": "Could not parse logs — check CI manually",
"failure_type": "other", "affected_files": [],
"error_snippet": logs[:200], "suggested_fix": "Review CI logs directly",
"severity": "medium", "is_recurring": False,
"jira_summary": f"CI failure — {workflow}",
"jira_description": f"Automated analysis failed. Run ID: {run_id}"
}
return FailureAnalysis(
run_id = run_id,
likely_cause = data.get("likely_cause", ""),
failure_type = data.get("failure_type", "other"),
affected_files = data.get("affected_files", []),
error_snippet = data.get("error_snippet", ""),
suggested_fix = data.get("suggested_fix", ""),
severity = data.get("severity", "medium"),
is_recurring = data.get("is_recurring", False),
jira_summary = data.get("jira_summary", "")[:80],
jira_description= data.get("jira_description", ""),
input_tokens = response.usage.input_tokens,
output_tokens = response.usage.output_tokens,
)
def _create_jira_ticket(self, analysis: FailureAnalysis) -> str:
"""Create a pre-filled Jira bug ticket for the CI failure."""
try:
priority_map = {
"critical": "Highest", "high": "High",
"medium": "Medium", "low": "Low"
}
issue = self.jira.create_issue(fields={
"project": {"key": os.getenv("JIRA_PROJECT_KEY", "ENG")},
"summary": f"[AI-AGENT] CI: {analysis.jira_summary}",
"issuetype": {"name": "Bug"},
"priority": {"name": priority_map.get(analysis.severity, "Medium")},
"description": analysis.jira_description,
})
logger.info(f"✓ Jira bug created: {issue.key}")
return f"{os.getenv('JIRA_URL')}/browse/{issue.key}"
except Exception as e:
logger.error(f"Failed to create Jira ticket: {e}")
return ""
def _notify_slack(self, author: str, workflow: str,
analysis: FailureAnalysis) -> None:
"""Send root cause analysis to Slack — plain English, actionable."""
severity_emoji = {
"critical": "", "high": "",
"medium": "", "low": ""
}.get(analysis.severity, "")
message = (
f"{severity_emoji} *[AI-AGENT] CI Failure — {workflow}*\n"
f"*Author:* @{author}\n"
f"*Cause:* {analysis.likely_cause}\n"
f"*Suggested fix:* {analysis.suggested_fix}\n"
f"*Ticket:* {analysis.ticket_url or 'Could not create ticket'}"
)
try:
self.slack.chat_postMessage(
channel=self.channel, text=message
)
logger.info(f"✓ Slack notification sent to {self.channel}")
except Exception as e:
logger.error(f"Slack notification failed: {e}")
def _escalate(self, workflow: str, analysis: FailureAnalysis) -> None:
"""Escalate recurring failures to team lead."""
escalation_channel = os.getenv("SLACK_ESCALATION_CHANNEL", "#engineering-leads")
try:
self.slack.chat_postMessage(
channel=escalation_channel,
text=(
f" *[AI-AGENT] Recurring CI Failure — escalating*\n"
f"Workflow: {workflow}\n"
f"Pattern: {analysis.likely_cause}\n"
f"This failure has occurred 3+ times. Human intervention required."
)
)
except Exception as e:
logger.error(f"Escalation failed: {e}")The architecture
We have five agents with real access: to your code repository, your tool administration for your project, and your communication tool. What are the common features of this team?
- They trigger automatically.
- They act without human initiation.
This is too much risky for shipping this to production, specifically on some environments where risk aversion is a common way to work. So before we ship this to production, we need to be explicit about how we ensure they don't cause harm.
The following architecture is based on seven layers to enhance the security and control features, all seven are required, none are optional.
1. Principle of Least Privilege
Every agent has its own dedicated API token, scoped to the minimum permissions it needs.
AGENT_PERMISSIONS = {
"scrum_master": {
"jira": ["browse_projects", "view_issues"], # read-only
"slack": ["chat:write"], # one channel
"github": [], # no access
},
"code_reviewer": {
"github": ["repo:read", "pull_requests:write"], # comment only
"slack": ["chat:write"],
"jira": [],
},
"doc_writer": {
"github": ["repo:read", "contents:write", "pull_requests:write"],
"jira": ["browse_projects", "view_issues"],
"slack": [],
},
"qa_agent": {
"jira": ["browse_projects", "create_issues"], # subtasks only
"github": ["contents:write"], # test branch only
"slack": [],
},
"ops_monitor": {
"github": ["actions:read"], # logs only
"jira": ["create_issues"], # bug creation only
"slack": ["chat:write"],
},
}No agent has admin, write:all, or any permission beyond what its specific job requires. This is enforced at the token level, even if a bug in the agent code tried to do something beyond scope, the token would reject it.
2. No Production Access, Ever
Every agent has its own dedicated API token, scoped to the minimum permissions it needs.None of the five agents have credentials to:
- Production databases
- Production deployment pipelines
- Infrastructure management tools (Terraform, CloudFormation, Kubernetes admin)
- Payment processing systems
- Customer data stores
This is a hard architectural constraint. It is not a configuration option. It is not enforced by the system prompt. It is enforced by the complete absence of credentials.The Ops Monitor reads CI logs. It does not have the ability to trigger a rollback, restart a service, or modify a database — regardless of what its analysis concludes.
3.Mandatory Audit Trail
Every agent action is logged with the [AI-AGENT] tag before it executes. The log includes: timestamp, agent name, action taken, input hash, token count, and the specific tool called.
class AuditLogger:
"""
Immutable audit log for all agent actions.
Write-only: agents can append, never modify or delete.
"""
def __init__(self, store_path: str = "audit/agent_actions.jsonl"):
self.store_path = store_path
os.makedirs(os.path.dirname(store_path), exist_ok=True)
def log(self, agent: str, action: str, details: dict) -> str:
"""Log an agent action. Returns the action ID."""
entry = {
"id": f"{agent}-{datetime.now(timezone.utc).strftime('%Y%m%d%H%M%S%f')}",
"tag": "[AI-AGENT]",
"agent": agent,
"action": action,
"details": details,
"timestamp": datetime.now(timezone.utc).isoformat(),
}
# Append-only write — agents cannot modify past entries
with open(self.store_path, "a") as f:
f.write(json.dumps(entry) + "\n")
return entry["id"]
audit = AuditLogger()
Every Slack message, every GitHub comment, every Jira ticket created, logged before it happens. If something goes wrong, you have a complete timeline.
4.Human Override on Every Action
Every agent action is labeled [AI-AGENT] in the output. Engineers can:
- Delete any GitHub comment posted by an agent
- Close any Jira ticket created by an agent
- Remove any Slack message posted by an agent (via Slack admin)
The override is one click. The label makes agent actions findable and distinguishable from human actions.
def tag_content(content: str, agent: str) -> str:
"""
Every agent output gets the [AI-AGENT] tag.
This makes it searchable, auditable, and overridable.
"""
return f"{content}\n\n_[AI-AGENT] {agent} · jardon.ai/ai-dev-squad_"
5.Rate Limiting and Daily Caps
Each agent has a hard daily action cap. If the cap is hit, the agent stops and notifies the team.
class RateLimiter:
"""
Hard daily caps per agent.
Prevents runaway agents from spamming APIs or running up costs.
"""
DAILY_CAPS = {
"scrum_master": 1, # one standup per day
"code_reviewer": 50, # max 50 PR reviews per day
"doc_writer": 20, # max 20 doc updates per day
"qa_agent": 30, # max 30 test generations per day
"ops_monitor": 100, # max 100 failure analyses per day
}
def __init__(self):
self._counts: dict[str, int] = {}
def check_and_increment(self, agent: str) -> bool:
"""Return True if agent is within daily cap, False if cap exceeded."""
today = datetime.now().strftime("%Y-%m-%d")
key = f"{agent}:{today}"
count = self._counts.get(key, 0)
cap = self.DAILY_CAPS.get(agent, 10)
if count >= cap:
logger.warning(f"[RATE LIMIT] {agent} hit daily cap of {cap}")
return False
self._counts[key] = count + 1
return True
rate_limiter = RateLimiter()
6.Kill Switch
Any agent can be disabled instantly without code deployment.
AGENT_STATUS_FILE = "config/agent_status.json"
def is_agent_enabled(agent: str) -> bool:
"""
Check if an agent is enabled before running.
Edit agent_status.json to disable any agent instantly.
No redeployment required.
"""
try:
with open(AGENT_STATUS_FILE) as f:
status = json.load(f)
return status.get(agent, {}).get("enabled", True)
except FileNotFoundError:
return True # default enabled if file missing
// config/agent_status.json
{
"scrum_master": {"enabled": true},
"code_reviewer": {"enabled": true},
"doc_writer": {"enabled": true},
"qa_agent": {"enabled": false, "reason": "Jira quota exceeded"},
"ops_monitor": {"enabled": true}
}
One file edit. Any agent disabled in seconds. No PR, no deployment, no engineering ticket.
7.Anomaly Detection
The orchestrator monitors agent behavior for patterns that indicate something is wrong.
class AnomalyDetector:
"""
Detects abnormal agent behavior and halts the agent if thresholds are breached.
"""
def check(self, agent: str, action_count: int, error_count: int,
time_window_minutes: int = 5) -> bool:
"""
Return False (halt) if behavior is anomalous.
Triggers:
- More than 10 actions in 5 minutes (possible loop)
- Error rate above 50% (possible API issue)
- Any single action taking more than 60 seconds
"""
if action_count > 10:
logger.critical(f"[ANOMALY] {agent}: {action_count} actions in {time_window_minutes}min — halting")
return False
if action_count > 0 and (error_count / action_count) > 0.5:
logger.critical(f"[ANOMALY] {agent}: {error_count}/{action_count} errors — halting")
return False
return TrueThe Orchestator
With all five agents and all seven safety layers, the orchestrator looks like this:
class DevSquadOrchestrator:
"""
The single entry point for all agent actions.
Enforces all seven safety layers before any agent runs.
"""
def __init__(self):
self.agents = {
"scrum_master": ScrumMasterAgent(),
"code_reviewer": CodeReviewerAgent(),
"doc_writer": DocWriterAgent(),
"qa_agent": QAAgent(),
"ops_monitor": OpsMonitorAgent(),
}
self.routing = {
"daily.standup": "scrum_master",
"github.pull_request": "code_reviewer",
"github.push.main": "doc_writer",
"jira.ticket.in_dev": "qa_agent",
"github.actions.failure": "ops_monitor",
}
self.rate_limiter = RateLimiter()
self.audit = AuditLogger()
self.anomaly = AnomalyDetector()
def route(self, event: dict) -> dict:
"""Route an event through all safety layers before execution."""
event_type = event.get("type", "unknown")
agent_name = self.routing.get(event_type)
if not agent_name:
return {"status": "unrouted", "event": event_type}
# Layer 6 — Kill switch check
if not is_agent_enabled(agent_name):
logger.warning(f"[KILL SWITCH] {agent_name} is disabled")
return {"status": "disabled", "agent": agent_name}
# Layer 5 — Rate limit check
if not self.rate_limiter.check_and_increment(agent_name):
return {"status": "rate_limited", "agent": agent_name}
# Layer 3 — Pre-action audit log
action_id = self.audit.log(agent_name, event_type,
{"event": event, "tag": "[AI-AGENT]"})
# Execute the agent
try:
result = self.agents[agent_name].handle(event)
except Exception as e:
logger.error(f"[ERROR] {agent_name} raised: {e}")
result = {"status": "error", "agent": agent_name, "error": str(e)}
# Layer 3 — Post-action audit log
self.audit.log(agent_name, f"{event_type}.complete",
{"action_id": action_id, "result": result})
return resultWhat This Squad Actually Changes
Looking back at the five agents as a system:
- For the individual engineer:They start each day knowing the sprint status without sitting through a standup. They open a PR and find a first review already posted. They start a ticket and find test stubs already written. When they break the build at 6pm, they get a Slack message with the exact cause and fix — not a generic notification at 8am.
- For the team:Documentation is current. Test coverage is started before implementation. CI failures are triaged before the team arrives in the morning. Code review has a first pass on every PR, regardless of whether senior engineers have time that day.
- For the organization:Every agent action is logged, tagged, and auditable. Every agent operates within scoped permissions. No agent touches production. Human engineers remain in control of every consequential decision — what gets merged, what gets closed, what gets escalated.
The AI Dev Squad is not a replacement for engineering judgment. It is a system that ensures engineering judgment is spent on problems that actually require it.
Thank you for following the AI Dev Squad series. All five agents, the orchestrator, and the safety architecture are available in the GitHub repository.
Sources and reference
- Anthropic — Claude API Documentation
- Atlassian — Jira REST API v3
- GitHub — REST API Documentation
- PyGithub — Python GitHub library
- Keep a Changelog — keepachangelog.com
- Nygard, M. — Architecture Decision Records
- Code — github.com/sjardon/ai-dev-squad