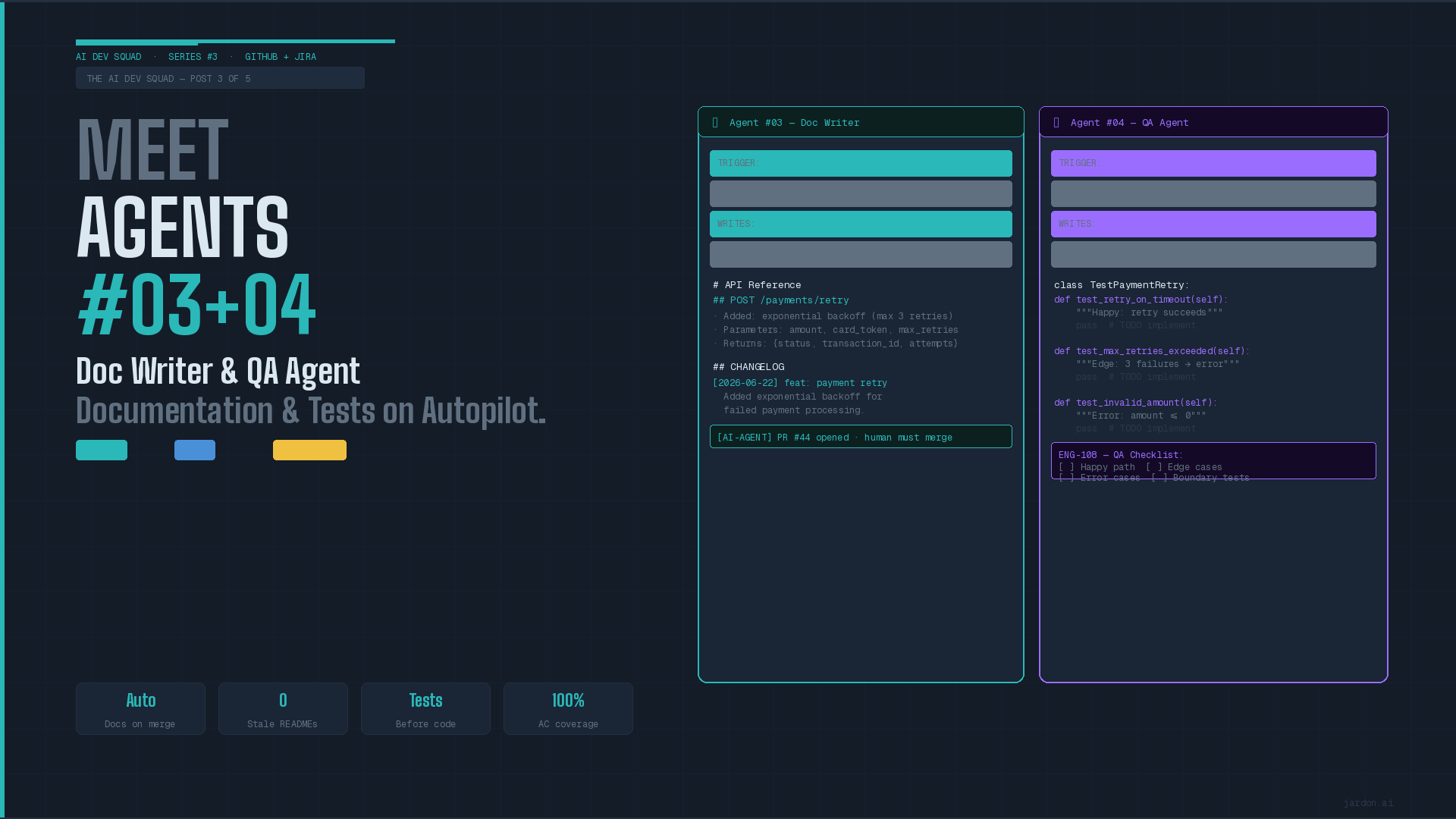
Agents #003 and #004: Doc Writer and QA Agent. Documentation and Tests on Autopilot
Documentation is always out of date. Tests are always written last, if at all. Two agents fix both problems simultaneously , one updates your README, CHANGELOG, and API docs on every merge; the other generates test scaffolding the moment a Jira ticket moves to development.
Let's be honest, two problems exists in almost every engineering team, regardless of size, experience or seniority:
- Documentation is always out of date. Not because we don't care, but because updating docs on every change or merge, competes with next feature and usually team and product owner prioritize development. This becomes a way of work and new joiners onboard with this mental model that's already wrong.
- Test are written last, or not at all. Typically, when developing new features, testers are not really owning the test because they are waiting for developers to finish. Sadly, their participation during daily meeting is focused on user acceptance test status and they don't write the automation test, integration test. This leads to miss edge cases, late bug finding and higher risk to introduce an incident to higher environments.
This is not good. On one hand, documentation even if it's not a high value artifact, it's the base for knowledge not only for new joiners, it's an educational tool, a base building block for the team and outside the team, and finally a communication tool across the organization. Good and updated documentation it's a sign of a solid team that understands the value of transparency. On the other hand, testing it's the last line of defense before any major issue goes to prod. Solid testing raises the bar within the team, forcing developers to think outside of the box, architects to design for failure and even users to think in catastrophic scenarios.
Let's focus on try to help teams with these two agents.
Agent #003. The doc writer
This agent will trigger when a push or merge to main branch on GitHub. The goal is to update README and CHANGELOG and even ADR draft if needed. This is the basic steps it will perform:
- Fetches the merge diff from GitHub
- Extracts the Jira ticket key from the commit message
- Reads the Jira ticket for context using the title, description, acceptance criteria.
- Sends everything to LLM, Claude in our case, with a structured prompt.
- Receives a JSON object with README update, CHANGELOG entry and ADR draft if an architectural change is detected.
- Opens a pull request with the documentation changes, tech lead must review the change.
This is important, and consistent with our previous design decisions, every documentation goes through a PR. Human sign-off is required. Not convinced? let's elaborate a few more reasons:
- Quality control. AI-generated documentation can miss intent, a human reviewing the doc PR takes a few mins to catch any error before reaching main.
- Audibility. PR creates a record, who merged it when and what was changed. For any medium size enterprise this matters.
The prompt
SYSTEM_PROMPT = """
You are a technical writer AI. You receive a code diff and a Jira ticket
and generate documentation updates.
Return a JSON object with this exact structure:
{
"readme_update": {
"section": "API Reference | Installation | Configuration | null",
"content": "markdown text to add or update, or null if no change needed"
},
"changelog_entry": "## [version] YYYY-MM-DD\\n### Added/Changed/Fixed\\n- ...",
"needs_adr": true | false,
"adr_draft": "full ADR in Michael Nygard format, or null",
"summary": "one sentence describing what changed"
}
ADR format (if needs_adr is true):
# ADR-XXX: [title]
## Status: Proposed
## Context: why this decision was needed
## Decision: what was decided
## Consequences: what changes as a result
Rules:
- Update README only if the change affects public-facing behavior
- CHANGELOG entry must follow Keep a Changelog format
- ADR is required for: new dependencies, breaking changes, architecture shifts
- Be concise — documentation should be shorter than the code it describes
You MUST NOT:
- Modify source code files (.py, .js, .ts, etc.)
- Invent API endpoints or features not present in the diff
- Push directly to main — always create a PR
- Return anything other than valid JSON
"""
Agent #004. The QA
This agent will trigger when Jira ticket changes from ready to in development. It will produce tests stubs with docstrings plus jira qa subtasks with full checklist. Tests written after implementation have a systematic bias: they test what the code does, not what it should do. The engineer writes the implementation, then writes tests that pass it. Edge cases that weren't implemented don't get tested because the engineer no longer remembers the acceptance criteria, they're focused on what they built. Tests written from the user story, before implementation, test what the feature should do according to the requirements. They fail until the implementation is correct. That's the entire point of TDD. The QA Agent does all of that automatically, the moment the ticket moves to development.

This is the basic workflow.
- Reads the jira ticket getting title, description, acceptance criteria.
- Sends to LLM with a structured prompt.
- Receives back a test plan including happy path, edge cases, error cases, boundary test and stubs.
- Writes the stubs to the feature branch on GitHub.
- Creates a Jira subtask with the full test checklist for QA lead sign-off.
The engineer starts writing code with tests already scaffolded. They fill in the implementation, run the tests, and ship. Edge cases are already accounted for, in writing, from the requirements.
SYSTEM_PROMPT = """
You are a QA engineer AI. You receive a Jira user story and generate
test cases and boilerplate test stubs.
Return a JSON object with this structure:
{
"test_plan": {
"happy_path": ["list of happy path scenarios"],
"edge_cases": ["list of edge cases"],
"error_cases": ["list of error/negative test cases"],
"boundary_tests": ["list of boundary/limit tests"]
},
"test_stubs": "complete Python pytest code with empty test functions and docstrings",
"jira_checklist": "markdown checklist for the QA Jira subtask",
"estimated_test_count": 0,
"coverage_areas": ["list of code areas this test suite covers"]
}
Test stub format:
import pytest
class TestFeatureName:
def test_scenario_name(self):
\"\"\"
User story: ENG-XXX
Scenario: [description]
Expected: [expected outcome]
\"\"\"
# Arrange
# Act
# Assert
pass
Rules:
- Generate stubs only — no implementation code (only pass statements)
- Include Arrange/Act/Assert comments in each stub
- Reference the Jira ticket key in every docstring
- Cover all acceptance criteria from the ticket
You MUST NOT:
- Write implementation code
- Invent requirements not present in the user story
- Close or modify the Jira ticket
- Return anything other than valid JSON
"""
The QA Agent generates scaffolding, not implementation.
Cost optimization
The Doc Writer and QA Agent have different cost profiles that require different strategies.
- Doc Writer:
- Fires once per merge to main, this is predictable and low frequency.
- Biggest cost lever: truncate the diff ('MAX_DIFF_CHARS = 5_000').
- Skip if diff contains only test files.
- QA:
- Fires when ticket moves to "In Development" , frequency = team velocity.
- Skip if ticket type is "Bug".
- Cache: if the same ticket triggers twice (re-assignment), skip if stubs already exist.
What humans still own?
- Review and merge the doc PR, catch AI misinterpretations or hallucinations.
- Update doc style guide and README structure.
- Implement the test stubs, fill in Arrange/Act/Assert.
- Add integration and E2E tests, agent generates unit stubs only.
- Decide what level of documentation and testing is appropriate for each feature.
The agents eliminate the boilerplate. The engineering judgment, what to test, how thoroughly, what to document, at what depth, remains entirely human.
What's next?
The final agent in the squad monitors your CI/CD pipelines, analyzes failures, creates pre-filled Jira tickets, and notifies the right engineer on Slack. The second half of that post covers the safety architecture that keeps all five agents from going rogue, the guardrails, audit trail, and kill switches that make this system trustworthy in production.
Remember, for a full implementation or consultation drop me a message.
SOURCES & REFERENCES
- Anthropic — Claude API Documentation
- Atlassian — Jira REST API v3
- GitHub — REST API Documentation
- PyGithub — Python GitHub library
- Keep a Changelog — keepachangelog.com
- Nygard, M. — Architecture Decision Records
- Code — github.com/sjardon/ai-dev-squad