Agent #002 - The Code Reviewer
Every pull request your team opens deserves a first review. Here is how to build an agent that reads every PR, detects bugs and security issues, posts structured feedback on Github and notifies. Before your first coffee
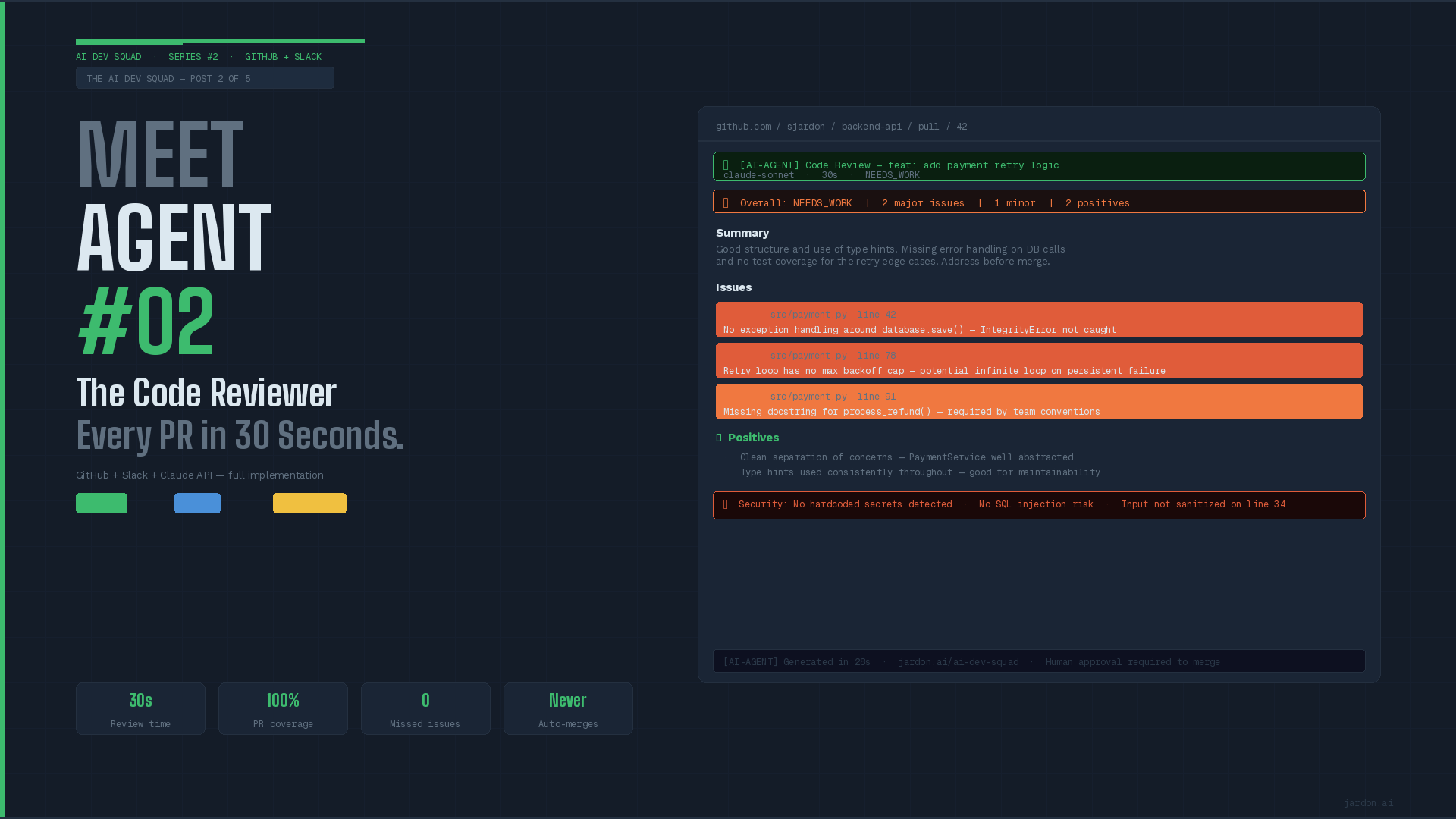
Code review is one of the highest-value in software engineering. It improves three main aspects at once: code quality, because typically second or four eyes catches any blind spot on the author's code; team knowledge, because reading each other's code build codebase and business knowledge; and engineering culture, because the habit of reviewing forces the team members to improve their quality. Studies from Google's DevOps research show that teams with strong code review practices, deploy more frequently, recover faster from incidents and have lower failure rates.
In most teams, Senior Engineers are in charge of this activity, and it makes perfect sense according to their experience and level of confidence and knowledge. But also, typically this person performs other key activities such as firefighting production issues, participate in a lot of meetings and unblocking daily activities with less experienced members of the team.

The second chapter of our AI team agents is focused on helping on these tasks. Give your team a boost with the Code Review Agent. This CR wingman will review your PR the moment it opens within 30 seconds, post structured feedback directly in gitHub. Do you need to add your code practices or internal policies, go ahead and make them part of this agent. Focus your most experienced team members on architecture or design, the agent will help with everything else.
What the agent does?
This is a non-limitative list of this agent tasks
- The trigger. When a pull request is opened or a commit is pushed, GitHub sends a web hook to the agent's endpoint
- The diff. The agent fetches the full diff from the GitHub API. Changed files, line-by-line changes, PR description
- Analyze. The diff is sent to your LLM, in this case Claude, with a structured prompt. Claude returns a JSON object with a rating, list of issues and line references, security checks and list of positives.
- The policies. Do you have significant internal policies and checks? Use a policies.yaml with code conventions, security requirements and compliance obligations. This result will be added to the report before committing to GitHub.
- Post to GitHub. The overall rating and policies are combined into an structured review comment in GitHub.
- Notification. A summary is posted to your dev channel including PR title, rating, issue count, link.
- Log for audit trail. Every action is logged as previously discussed. We will use [AI-AGENT] tag along with the PR number, model used, token count, policies triggered.
The prompt
The following is a base prompt. We will apply the seven-rules for the good prompting.
SYSTEM_PROMPT = """
You are a senior software engineer performing a code review.
You receive a GitHub pull request diff and description.
Return ONLY a valid JSON object — no preamble, no markdown fences.
Structure:
{
"overall_rating": "APPROVED | NEEDS_WORK | CRITICAL",
"summary": "2-3 sentence assessment",
"issues": [
{
"severity": "critical | major | minor | suggestion",
"file": "path/to/file.py",
"line": 42,
"comment": "Explanation + suggested fix"
}
],
"security": {
"has_issues": false,
"findings": []
},
"positives": ["at least one positive — always required"],
"estimated_human_review_minutes": 10
}
Severity: critical=security/data loss, major=bug/missing error handling,
minor=style/docs, suggestion=optional improvement.
Rating: APPROVED=no critical/major, NEEDS_WORK=major issues, CRITICAL=any critical.
MUST NOT: approve/merge PRs, modify files, access other branches,
request changes via GitHub formal review API, return non-JSON.
"""
The following step transforms a generic code reviewer to your organization's guardian-rules. Most code review tools apply "universal rules" such as OWASP, PEP8. They are useful, but in my experience there are a bunch of internal rules that cover naming conventions, logging practices, compliance obligations and security baselines. This can be covered with a policy file that can be updated as needed. No redeployment required
policy.yaml
Level 1. Code conventions
- id: CONV-001
severity: minor
description: "No bare print() statements in production code"
pattern: "^\\+.*\\bprint\\s*\\("
message: "Use logger.info/warning/error instead of print()."
- id: CONV-004
severity: major
description: "Exception handling must not use bare except"
pattern: "^\\+\\s*except\\s*:"
message: "Bare except catches SystemExit. Use except Exception as e:"
Level 2. Security Rules
- id: SEC-002
severity: critical
description: "PII must never be logged in plain text"
pattern: "^\\+.*(logger|log|print).*\\b(email|phone|ssn|card_number)\\b"
message: "Potential PII in log statement. Mask before logging."
- id: SEC-004
severity: major
description: "Financial amounts must use Decimal, not float"
pattern: "^\\+.*(amount|price|balance|fee).*=.*[0-9]+\\.[0-9]+"
message: "Float arithmetic causes rounding errors. Use Decimal."
Level 3. Compliance
- id: COMP-001
severity: major
description: "Financial transactions must generate audit trail"
pattern: "^\\+.*(transfer|payment|withdrawal|deposit).*def\\s"
message: "Financial operation detected. Ensure audit_log() is called."
- id: COMP-004
severity: critical
description: "Encryption required for sensitive data at rest"
pattern: "^\\+.*(card_number|account_number|iban).*=(?!.*encrypt)"
message: "Sensitive identifier stored without encryption. Use field-level encryption."Remember, this is just an idea. The sky is the limit. The reason behind using an independent regex-based rule is not depending on the LLM that might flag a PII leak missing the context. Also this leverages costs on using the LLMs tokens.
The implementation
import re, yaml
def load_policies(policy_file: str = 'policies.yaml') -> dict:
try:
with open(policy_file) as f:
return yaml.safe_load(f)
except FileNotFoundError:
logger.warning('policies.yaml not found, running without custom policies')
return {'conventions': [], 'security': [], 'compliance': []}
def run_policy_engine(diff: str, policies: dict, changed_files: list) -> list:
violations = []
all_rules = (
policies.get('conventions', []) +
policies.get('security', []) +
policies.get('compliance', [])
)
for rule in all_rules:
for line_num, line in enumerate(diff.splitlines(), 1):
if re.search(rule['pattern'], line):
violations.append({
'severity': rule['severity'],
'file': _extract_filename(diff, line_num),
'line': line_num,
'comment': f"[{rule['id']}] {rule['message']}",
'source': 'policy_engine',
'rule_id': rule['id'],
})
return violations
def merge_findings(claude_issues: list, policy_violations: list):
all_issues = claude_issues + policy_violations
severity_order = {'critical': 0, 'major': 1, 'minor': 2, 'suggestion': 3}
all_issues.sort(key=lambda x: severity_order.get(x['severity'], 4))
# Escalate rating if critical policy violation found
has_critical = any(
v['severity'] == 'critical' and v.get('source') == 'policy_engine'
for v in policy_violations
)
return all_issues, 'CRITICAL' if has_critical else None
The policies.yaml is versioned in your repo alongside your code. When compliance requirements change, you update the file, then the agent picks it up on the next run. No redeployment. No PR. No engineering ticket.
What about the money?
Unlike the Scrum master, the code reviewer fires on every PR. In a two pizza team, pepperoni please, that could be something between 10 to 20 per day.
The following controls are very important here:
- Diff control
Large PRs can have +10,000 lines. Send the full diff will burn your wallet and does not bring any improvement in quality. Truncate aggressively
MAX_DIFF_CHARS = 6_000 # ~400-500 lines
diff = full_diff[:MAX_DIFF_CHARS]
if len(full_diff) > MAX_DIFF_CHARS:
diff += f"\n\n[TRUNCATED — {len(full_diff):,} chars total]"
- Skip trivial PRs automatically
Documentation, lock files, and config changes don't benefit from LLM review.
SKIP_PATTERNS = [
r'\.md$', r'\.txt$', r'\.json$',
r'package-lock', r'yarn\.lock', r'\.gitignore',
]
def should_skip(changed_files: list) -> bool:
return all(
any(re.search(p, f) for p in SKIP_PATTERNS)
for f in changed_files
)
- Set a daily review cap
MAX_REVIEWS_PER_DAY = 30
If your team opens more PRs than the cap allows, log it and notify, you team can manually trigger reviews for the remaining ones.
- Deduplicate on re-push
Store a hash of the diff per PR. If the developer pushes a trivial commit (fixing a typo), skip the review.
5. Log token usage on every call
logger.info(
f"[COST] PR #{pr_number} | "
f"input={response.usage.input_tokens} "
f"output={response.usage.output_tokens}"
)
A 10-team company running 15 PR reviews per day costs roughly $0.50–$2.00 per day at current mid-tier model pricing.
What the agent cannot do?
The code reviewer has read access to the PR diff and comment-posting permissions. It cannot:
- Approve or merge requests
- Access any other branch other than the PR branch
- Push commits or modify files in the repository
- Access any other system than needed.
What the human reviewer still owns?
Agent handles the repetitive work, human has the final word.
- Architecture decisions. This requires system context, roadmap and understands trade-offs.
- Intent validation. Is this really solving the problem? I dunno, you tell me
- Formal approving. This is human accountability
- Knowledge transfer. Teaching junior engineers through review comments requires relationship and context.
- Edge cases judgement. This requires business knowledge, no AI can help you here.
- Security sign-off. Agent flags, human decides. Security decisions carry responsibilities Peter.
What's next?
In this chapter we learned that this agent reduces the time a human reviewer spends on mechanical checks. Flaggin obvious bugs, formats and error handling from 45 mins to 3 mins. That's a lot of time that you can request your Senior engineers to help you on significant and valuable tasks.
On the next chapter of this series, we will go with the QA agent and doc writer. Yes we can cover both in one chapter.
SOURCES & REFERENCES
- Anthropic — Claude API Documentation
- GitHub — REST API — Pull Requests
- GitHub — Webhooks documentation
- PyGithub — Python GitHub library
- Slack — Bolt SDK for Python